Introduction¶
Basic Information¶
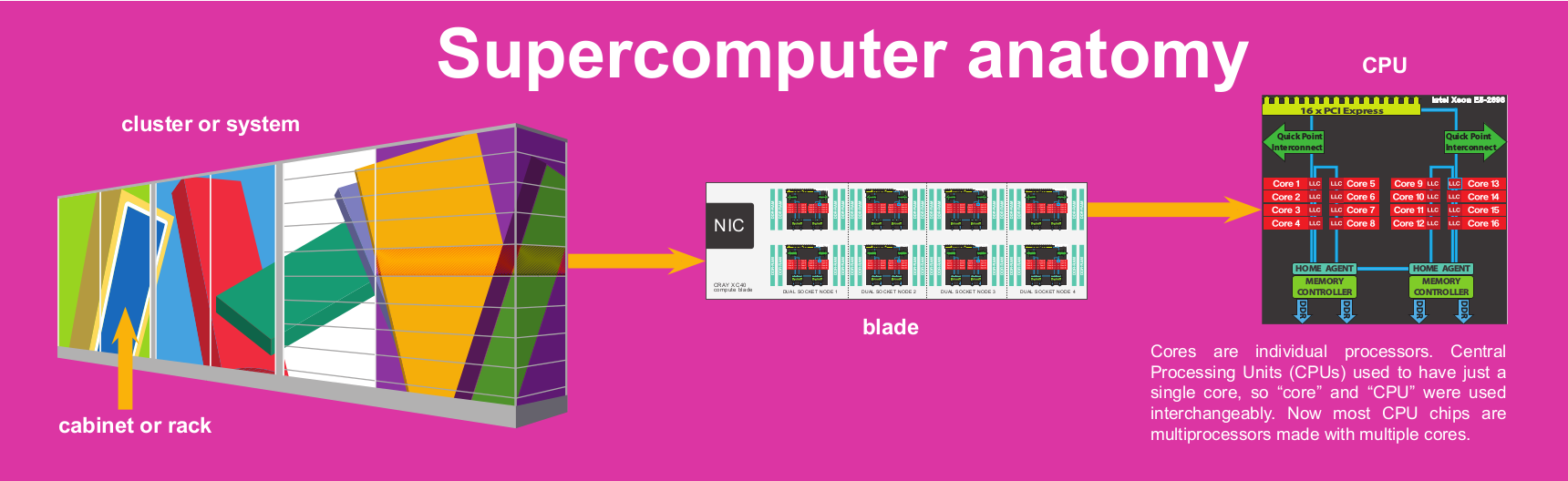
Clusters, nodes, processors, and cores¶
Like most high-performance computing facilities, PDC mainly features clusters. A computer cluster is in the broad sense terminology for a supercomputer, consisting of a set of connected computers working together so that they can be viewed as a single system.
A node is the individual computer part of each cluster. Nodes are analogous to the computers we use everyday.
And each node in turn has processors made up of computing entities called cores.
See also
For a more technical overview, please visit the Resources page.
Deciding whether you need PDC for your work¶
The key feature of PDC systems (or most HPC resources in general) is large-scale parallelization of computations. PDC resources are used in a wide-range of scientific disciplines. If you want to find out if you work could benefit from PDC resources, check if:
-
your application require large computional resources
-
your application require large memory resources
-
your application require GPUs
-
your application can be parallelized
If you decide to use PDC resources, welcome on board! PDC provides you with:
-
supercomputer systems for large simulations and calculations
-
systems for processing data before and after simulations or calculations
-
software for simulation and modelling
-
short term storage for large volumes of data
-
assistance with using PDC’s computing and storage resources
-
experts in different research fields to assist you with using and/or scaling software
Who may use PDC’s HPC services¶
PDC’s resources are available for both business and academic research. Companies wanting to use PDC’s systems should contact business-unit@pdc.kth.se to discuss their requirements. Academic researchers (from Sweden or Europe) may apply for free time/storage allocations at PDC. Swedish academic researchers and their collaborators will need to apply for an allocation of time/storage for their projects via NAISS.
Account and Time Allocation¶
Before starting using PDC resources, you will need to get an account. Each user account must belong to one or more Time Allocations, since we allocate resources and manage job queueing based on the Time Allocation you belong to and not based on your individual user account. Each Time Allocation includes the following information:
-
list of users belonging to that Time Allocation
-
number of corehours allocated per 30 days period for all members of the Time Allocation
-
an expiration date for the Time Allocation
-
list of clusters available for running jobs
When you submit jobs in a cluster, you should belong to at least one Time Allocation, or the submission will fail. Using Time Allocations allows us to:
-
Prioritize your submitted jobs compared to other user’s jobs.
-
Keep track of compute-time used within the last 30 days by users and projects.
How much resources will be needed: corehours¶
At PDC, we allocate compute-time on our systems in corehours and you are granted an amount of corehours on a particular system. Corehours equals the number of cores used in how many hours. A time allocation gives you a certain amount of corehours evenly split over the months of the time allocation.
Clusters at PDC¶
You can find information about the clusters at PDC at https://www.pdc.kth.se/hpc-services/computing-systems
Basic Linux for new HPC users¶
Working with PDC resources requires a basic understanding of Linux systems. Some of our users are new to using Linux-based systems and have asked for introductory materials. Here is a collection for the basic command-line operations needed to get started with PDC.
Using commands in the shell¶
The shell is the program from which the user controls everything in a text-interface. When you login to a PDC system remotely, you are already in the shell window of the system. If you login to your own system, you are probably on a graphical screen. From there, search for terminal or Ctrl+Alt+T to enter the shell terminal. In the shell, you can start typing commands to perform some action. The default shell on the PDC clusters is bash.
Useful Shell commands¶
Upon login we are greeted with the shell
ssh user@dardel.pdc.kth.se
Last login: Fri Aug 8 10:14:59 2017 from example.com
user@dardel-login-1:~> _
Bash: Files and directories¶
-
Command pwd tells me where I am. After login I am in the “home”directory
pwd /cfs/klemming/home/u/user -
I can change the directory with cd
cd Private /Private pwd /cfs/klemming/home/u/user/Private
-
I can go one level up with cd ..
-
I can return to my HOME folder with cd
-
List the contents with ls -l
user@machine:~/tmp/talks ls -l total 237 drwx------ 3 user csc-users 2048 Aug 17 15:21 img -rw------- 1 user csc-users 18084 Aug 17 15:21 pdc-env.html -rw------- 1 user csc-users 222051 Aug 17 15:22 remark-latest.min.js
Bash: creating directories and files¶
-
We create a new directory called results and change to it
mkdir results cd results
-
Creating and editing files
-
Textfiles can be edited on your local computer and then transferred.
-
Textfiles can also be edited locally using text editor like nano/emacs/vim.
-
Copying, moving renaming and deleting¶
# copy file
cp draft.txt backup.txt
# recursively copy directory
cp -r results backup
# move/rename file
mv draft.txt draft_2.txt
# move/rename directory
mv results backup
# move directory one level up
mv results ..
# remove file
rm draft.txt
# remove directory and all its contents
rm -r results
File permissions with chmod¶
In Linux systems all files have a user, a group and a set of privileges which determines what resources a user can access. Every file has three different kind of access: read(r), write(w) and execute(x), as well as three different kind of permissions depending on if the person is the owner(u=user) of the file, in the same group(g) or someone else(o=other).
chmod g+w file
Adds(+) write(w) permissions for group(g) to the file.
There is another way to set the permissions by using numbers. Assume that each permission equals the number listed below:
|
Number |
Type |
|---|---|
|
0 |
no permissions |
|
1 |
execute |
|
2 |
write |
|
4 |
read |
chmod 753 file
Gives the user the read, write and execute permission(4+2+1), whereas users in the same group get read and execute permissions (4+1) while others get write and execute permissions (2+1).
Access Control Lists¶
For more fine grained control of access to files, so called POSIX ACLs (Access Control Lists) can be used. An ACL allows the owner of a file or directory to control access to it on a user-by-user or group-by-group basis. To view and modify an ACL, the commands getfacl and setfacl are used.
getfacl¶
The command getfacl is used to get file access control lists (ACLs)
getfacl dir
# file: dir1
# owner: lama-tst
# group: users
user::rwx
group::r-x
other::r-x
the directory dir1 is owned by the user lama-tst with permissions read(r), write(w) and execute(x). The permissions of the group and others are set to r-x which means that the group and others can read and execute.
Note
Use option -c to skip the comment header.
setfacl¶
setfacl -m user:jon:rwx dir1
getfacl -c dir1
user::rwx
user:jon:rwx
group::r-x
mask::rwx
other::r-x
Now the user jon has been added and can access to dir1 with permission read(r), write(w) and execute(x).
Note
The options -x is used to remove entries from the ACLs of file and -R to recurse into subdirectories.
Bash: history and tab completion¶
-
history preserve commands used
history 689 cd .. 691 cd Documents/ 692 cp -r introduction_PDC /cfs/klemming/home/h/hzazzi/Documents/Presentations 693 ssh dardel.pdc.kth.se 694 cd introduction_PDC/ 695 ls -l 696 pwd 697 history -
If I want to repeat…
!696 pwd ~/Documents/introduction_PDC -
Use also the TAB key for completion
-
CTRL/R to search for previous commands
-
Arrows up/down to scroll for earlier commands
Bash: finding things¶
-
Extract lines which contain an expression with grep
# extract all lines that contain searchme grep searchme draft.txt
-
If you do not know what a UNIX command does, examine it with man
man [command]
-
Find files with find
find ~ | grep lostfile.txt
-
We can pipe commands and filter results with |
grep energy results.out | sort | uniq
Bash: Redirecting output¶
-
Print content of a file to screen
cat test.out
-
Redirect output to a file
cat test.out > myfile.txt
-
Append output to a file
cat test.out >> myfile.txt
Bash: Writing shell scripts¶
#!/bin/bash
# here we loop over all files that end with *.out
for file in *.out; do
echo $file
cat $file
done
We make the script executable and then run it
# Make it executable
chmod u+x my_script
# run it
./my_script
Arguments to script can be passed by using $¶
File example
#!/bin/bash
echo "Hi" $1 $2
./myscript Nils Nilsson
Hi Nils Nilsson
- $1..$X:
-
First…Xth argument
To start executing such scripts, you would need to start with a text-editor. Choosing a text-editor is a matter of personal choice, with Vim and Emacs being traditional and popular programs. There are also many other new and interesting editors to choose from. Open your favorite text-editor and copy-paste the file example above and save with file as <script>. Then run the script by typing ./<script>.
Information about shell commands¶
Information about a commands can be retrieved from the manual
man <cmd>
Also you can get information about where the executable lies
which <cmd>
Executing your software¶
Most commands are quite intuitive acronyms and are easy to remember once you start using them. The usual syntax is
command -option1 arg1 -option2 arg2
where command is the name of the command, -option1 and -option2 specifies the particulars of the command (they are optional, there can be as many options as the specific command permits), and arg1 and arg2 are the value of the corresponding options. In general
command -h
Prints information about what options and arguments you can enter.
Editing your files¶
Editing your files on our cluster can be done with several text editors. Emacs and vi/vim are available on all PDC clusters and can be opened by
$ emacs [filename]
$ vi [filename]
$ vim [filename]
In addition, nano is available on Dardel as a module
$ module PDC
$ module nano
$ nano [filename]
For Linux beginners, nano might be a good editor to start with. Emacs and vi have steeper learning curves, so a reference guide is provided here for the most common operations using these editors.
Emacs
A complete tour of using emacs can be found at https://www.gnu.org/software/emacs/tour/
Below is a table summarizing the most frequently used operations. C-x means pressing simultaneously the control-key and x, C-x 2 means first pressing both control-key and x and then pressing 2, C-x C-s means first pressing control-key and x followed by control-key and s, and M-x means pressing the meta-key (Alt-key) and x simultaneously.
|
Keyboard command |
Purpose |
|---|---|
|
$ emacs foo.dat |
open foo.dat for editing |
|
C-x C-s |
save file |
|
C-x C-c |
quit emacs |
|
C-x C-w foo.dat |
save file as foo.dat |
|
C-_ or C-/ |
undo last change (can be repeated) |
|
C-g |
cancel current command |
|
C-s |
incremental search |
|
M-% |
Query replace |
|
C-f |
Move forward one character |
|
C-b |
Move backward one character |
|
M-f |
Move forward one word |
|
M-b |
Move backward one word |
|
C-n |
Next line |
|
C-p |
Previous line |
|
C-a |
Beginning of line |
|
C-e |
End of line |
|
M-< |
Beginning of buffer (file) |
|
M-> |
End of buffer |
|
C-k |
Kill (cut) line |
|
C-u 10 C-k |
Kill 10 lines (C-u <N> can be used to repeat any command) |
|
C-y |
Yank (paste) line |
|
C-SPC |
Set mark at current location |
|
C-w |
Kill (cut) region between current location and last mark |
|
M-w |
Save (copy) region |
|
C-x ( |
Start defining keyboard macro |
|
C-x ) |
End defining macro |
|
C-x e |
Execute macro once |
vi/vim
You can find tips and tricks for using vi at https://www.cs.colostate.edu/helpdocs/vi.html
Below is a table summarizing the most frequently used operations of vi/vim.
|
Keyboard command |
Purpose |
|---|---|
|
$ vim foo.dat |
open foo.dat for editing |
|
i |
enter insert mode, insert before the cursor |
|
a |
enter insert mode, insert (append) after the cursor |
|
o |
enter insert mode, append a new line |
|
Esc |
exit insert mode |
|
:w |
save |
|
:q |
quit |
|
:wq |
save and quit |
|
:q! |
quit without save |
|
u |
undo last change |
|
Ctrl-r |
redo last change |
|
h |
move cursor left |
|
j |
move cursor down |
|
k |
move cursor up |
|
l |
move cursor right |
|
gg |
move to the beginning of file |
|
G |
move to the end of file |
|
10G |
move to line 10 |
|
x |
delete 1 character |
|
dw |
delete 1 word |
|
dd |
delete 1 line |
|
d5d |
delete 5 lines |
|
yyp |
duplicate 1 line |
|
/pattern |
search for pattern |
|
?pattern |
search backward for pattern |
|
n |
repeat search in same direction |
|
N |
repeat search in opposite direction |
|
:s/old/new/ |
replace the first old with new in the current line |
|
:s/old/new/g |
replace all old with new in the current line |
|
:%s/old/new/g |
replace all old with new throughout file |
Learn more at http://www.fprintf.net/vimCheatSheet.html
The apperance of vim can be configured via the ~/.vimrc file. Below is an example
syntax on
filetype plugin indent on
set autoindent
set hlsearch " highlight search
set number " show line number
set ruler " show ruler at bottom right
" Return to last edit position when opening files
autocmd BufReadPost *
\ if line("'\"") > 0 && line("'\"") <= line("$") |
\ exe "normal! g`\"" |
\ endif
Further information¶
See also
- The Linux Command Line by William E. Shotts, Jr.
-
This book introduces the linux command line from the basics, and moves on to customizing the working environment and then finally to shell scripting. The entire book is available for free from the authors web page, and if you would like a paper copy you can order one from the publisher.
- UNIX / Linux Tutorial for Beginners
-
The University of Surrey has an online tutorial that introduces the linux command line. The web page also has links to other recommended linux books.
Glossary¶
Here you will find the basic terminologies and quick reference materials.
- cluster¶
-
Computer cluster is in the broad sense the terminology for a supercomputer, consisting of a set of connected computers working together so that they can be viewed as a single system. See resources to examine what clusters PDC currently has available.
- node¶
-
Nodes are components of a cluster and analogous to the computers we use every day. A supercomputer consists of a number of nodes that perform computations and run an own instance of the operating system.
- processor¶
-
component of each node. Each node has a number of processors that are analogous to the CPU (Central processing unit) in a personal computer.
- core¶
-
component of each processor. The actual computing entity.
- Time Allocation¶
-
Time Allocation is the technical term for “Project” that users need to be a part of to use the supercomputer. Time allocation contains information about the project and how much resources that have been allocated to the project. There are different types of time allocation depending on the size of the allocation, but the instructions for running jobs are the same.
- Principal Investigator (PI)¶
-
Principal Investigator is the “Project manager” of a time allocation. This user can add/remove users from the project and is usually the one that applied for the time allocation. All project related utilities are managed through SUPR, https://supr.naiss.se
- corehours¶
-
Corehours refers to the number of processor units (cores) used to run a simulation multiplied by the duration of the job (t) in hours. Corehours (c) can be calculated if the number of nodes (n), the duration in hours (t) and the number of cores per node (cpn) are known: c = n*cpn*t
- NAISS¶
-
NAISS or National Academic Infrastructure for Supercomputing in Sweden is the infrastructure organization for high-performance computing, storage and data services for academic users in Sweden.
- SUPR¶
-
SUPR or Swedish User and Project Repository is the NAISS database used to keep track of persons, projects, project proposals and more. https://supr.naiss.se
- NAC¶
-
NAC or National Allocations Committee handles all larger applications and allocations of NAISS.
- NAC-wg¶
-
National Allocations Committee Working Group is a group comprising of NAC members and experts from the various HPC centres in Sweden.
- SLURM¶
-
SLURM or Simple Linux Utility for Resource Management is an open-source cluster management and job scheduling system extensively used by PDC.
- Kerberos¶
-
Kerberos is a computer network authentication protocol. It works on the basis of creating a ticket that is used for secure communication. You need to create a Kerberos ticket to log in to the clusters, run programs and get access to the home directory and transfer files.
- CFS/Lustre¶
-
Lustre is a high-performance parallel file system which is mounted on the PDC clusters. Lustre provides fast access to large data files needed for large parallel applications, but is less suitable for dealing with many small operations on a large number of files.