How to Run Jobs¶
Many researchers run their program on PDC’s computer systems, often simultaneously. For this, the computer systems need a workload management and job scheduling. For job scheduling PDC uses Slurm Workload Manager .
When you login to the supercomputer with ssh, you will login to a designated login node in your Klemming home directory. Here you can modify your scripts and manage your files.
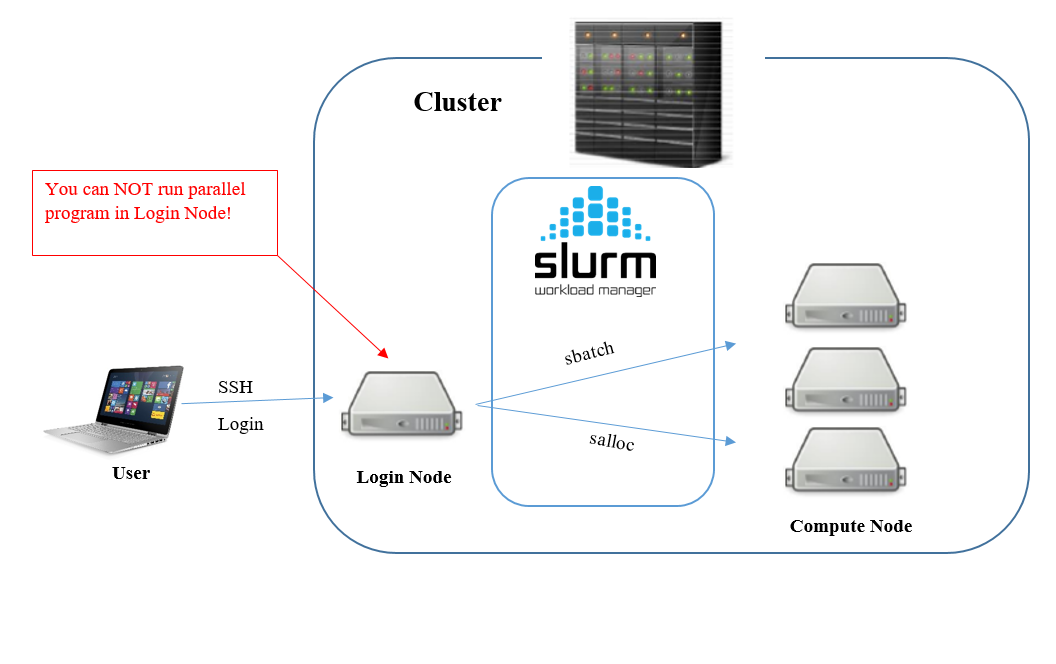
To run your script/program on the computer nodes, you can do it in one of the following ways.
How jobs are scheduled¶
The queue system uses two main methods to decide which jobs are run. These are called fair-share and backfill. Unlike some other centers, the time a job has been in the queue is not a factor.
Backfill¶
As well as having a main queue to ensure that the systems are as full as possible, the job scheduling system also implements “backfill”. If the next job in the queue is large (that is, it will need lots of nodes to run), the scheduler collects nodes as they become free until there are enough to start running the large job. Backfill means that the scheduler looks for smaller jobs that could start on nodes that are free now, and which would finish before there are enough nodes free for the large job to start. For backfill to work well, the scheduler needs to know how long jobs will take. So, to take advantage of the possibility of backfill, you should set the maximum time your job needs to run as accurately as possible in your submit scripts.
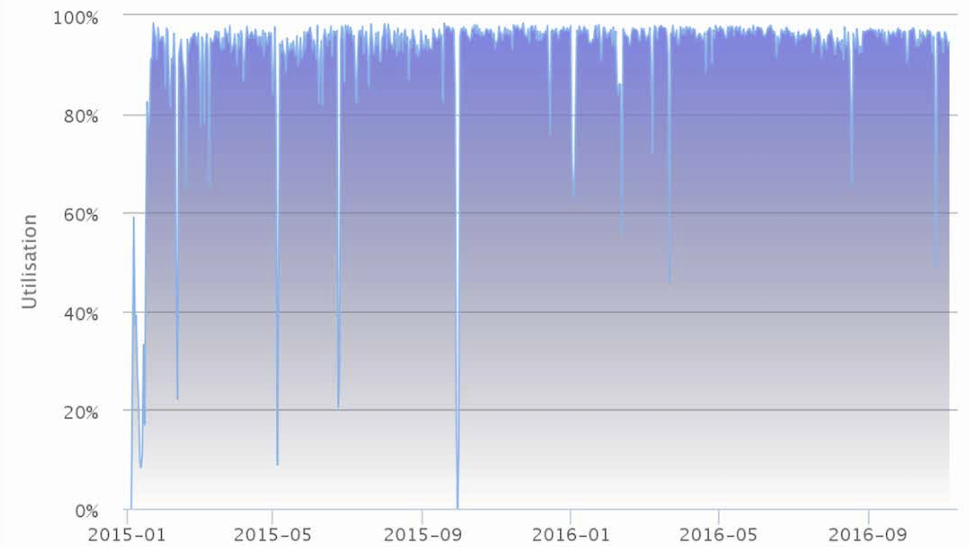
This graph shows the percentage of the nodes on Beskow (previous PDC’s supercomputer) that were in use on different dates from early 2015 till late 2016. You can see how the scheduler makes good use of Beskow as nearly all of the available nodes are being used all the time.
Note: All researchers sharing a particular time allocation have the same priority. This means that if other people in your time project have used up lots of the allocated time recently, then any jobs you (or they) submit within that project will be given the same low priority.
Example of scheduling¶
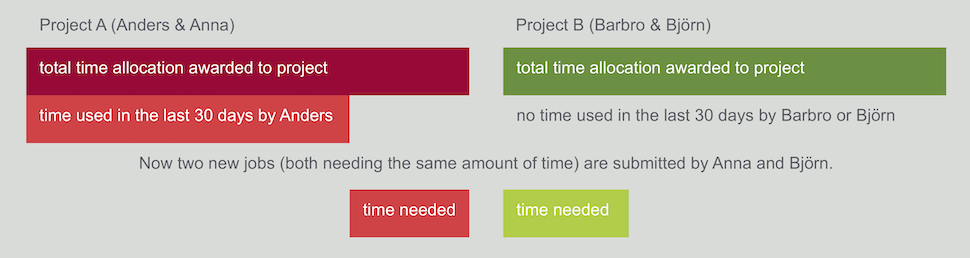
Of course both Anna and Björn would like their jobs to be run as soon as possible.
However, in the current situation, the scheduler will give priority to Björn’s job as his project (B) has not used as much of its time allocation recently as project A has used of their allocation.
The fact that Anna has not used any time herself does not make any difference as it is the total amount of time recently used by each project that is taken into consideration when deciding which job will be scheduled next.
How to submit jobs¶
Jobs can be submitted to PDC clusters in several ways. Both by sending jobs to the job queue or by booking and running a node interactively.
Dardel compute nodes¶
Compute nodes on Dardel have 4 different flavors with different amounts of memory. A certain amount of the memory is reserved for the operating system and system software, therefore the amount of memory available for user software is also listed in the table below. All nodes have the same dual socket processors, for a total of 128 physical cores per node.
|
Node type |
Node count |
RAM |
Partition |
Available |
Example used flag |
|---|---|---|---|---|---|
|
Thin node |
700 |
256 GB |
main, shared, long |
227328 MB |
|
|
Large node |
268 |
512 GB |
main, memory |
456704 MB |
|
|
Huge node |
8 |
1 TB |
main, memory |
915456 MB |
|
|
Giant node |
10 |
2 TB |
memory |
1832960 MB |
|
More details on the hardware is available at https://www.pdc.kth.se/hpc-services/computing-systems/about-dardel-1.1053338.
Different node types are allocated based on the SLURM partition (-p) and the --mem or --mem-per-cpu flags. By default, any free node in the partition can be allocated to the job. Using the --mem=X flag restricts the set of eligible nodes to those with at least X amount of available memory.
The following configuration allocates one node with at least 250 GB of available memory in the main partition, i.e. a large or huge node:
#SBATCH --mem=250GB
#SBATCH -p main
The --mem flag imposes a hard upper limit on the amount of memory the job can use. In the above example, even if the job is allocated a node with 1 TB of memory, it will not be able to use more than 250 GB of memory due to this limitation.
Dardel partitions¶
The compute nodes on Dardel are divided into four partitions. Each job must specify one of these partitions using the -p flag. The table below explains the difference between the partitions. See the table above for descriptions of the various node types.
|
Partition name |
Characteristics |
|---|---|
|
main |
Thin, large and huge nodes Job gets whole nodes (exclusive) Maximum job time 24 hours |
|
long |
Thin nodes Job gets whole nodes (exclusive) Maximum job time 7 days |
|
shared |
Thin nodes Jobs are allocated to cores, not nodes By default granted one core, get more with Job shares node with other jobs Maximum job time 7 days |
|
memory |
Large, huge and giant nodes Job gets whole nodes (exclusive) Maximum job time 7 days |
|
gpu |
GPU nodes Job gets whole nodes (exclusive) Maximum job time 24 hours |