Preparing GROMACS for Heterogeneous Exascale HPC Systems
Szilárd Páll, PDC, & Andrey Alekseenko, Scilifelab & Department of Applied Physics, KTH
GROMACS is an open-source molecular dynamics (MD) simulation package that is one of the most widely used high-performance computing (HPC) codes in Sweden and worldwide, both in academia and industry. The development is led by a Stockholm-based team from the KTH Royal Institute of Technology (KTH) and Stockholm University (SU), with major contributions recently being developed at PDC. These have included advances in application programming interfaces (APIs), algorithms and parallelisation.
GROMACS has a strong focus on performance thanks to state-of-the-art parallel algorithms and the use of bottom-up performance optimisation. Portability in practice is also a major objective which is achieved by using hardware abstraction layers for single instruction, multiple data (SIMD) units and for graphics processing units (GPUs), and the use of standards-based programming languages and APIs (whenever possible), as well as extensive testing on a wide range of architectures and platforms using automated continuous integration (CI), regular HPC deployments, and integration into multiple Linux distributions.
With PDC’s new Dardel system being based on AMD’s heterogeneous exascale architecture, which is also used in the LUMI system in Finland and in the Frontier system at the Oak Ridge National Laboratory (ORNL) in the USA (respectively the first and third systems on the recently announced 59th TOP500 list [1]), supporting these architectures in GROMACS has required long-term investments in both algorithms and parallelisation, as well as recent work on adopting new GPU frameworks. GROMACS has embraced GPUs for nearly a decade: the first official release with native GPU support came out nearly a decade ago in early 2013. At its core, it was a bottom-up redesign of the simulation engine, starting with reformulating key MD algorithms for modern processor microarchitectures combined with a heterogeneous multi-level parallelisation scheme [2].
From the start, the GROMACS MD engine has been heterogeneous, making use of both CPUs and GPUs for performance and flexibility, plus it is multi-level as it directly targets each level of hardware parallelism from SIMD vector units through multicore non-uniform memory access (NUMA) accelerators to multi-node cluster topologies. Together these make it one of the fastest MD engines. Embracing heterogeneity in the early phases of parallelisation design enabled the GROMACS engine to evolve features without needing to port everything to GPUs, as well as making it possible to easily adapt to hardware changes (like faster GPUs or denser heterogeneous nodes), while also maintaining support for a broad range of features and at the same time demonstrating excellent performance on multiple generations of hardware [3,4,5]. This design remains at the foundation of the GROMACS parallelisation that targets various system architectures. However, in anticipation of a changing exascale HPC hardware landscape, we initiated research on algorithms and parallelisation techniques to efficiently target future architectures within the frame of the Swedish Exascale Computing Initiative (SeCI) Swedish Foundation for Strategic Research (SSF) project, which was led by Erwin Laure in collaboration with the GROMACS team.
As a result, further improvements were made to key algorithms; we designed a dual-pair list algorithm for pair interactions which extends the accuracy-based formulation of our original work to improve regularised data reuse. In addition, we started a redesign of the original force-offload heterogeneous setup and GPU-resident parallelisation (see below) was designed and developed in a close codesign collaboration with NVIDIA.
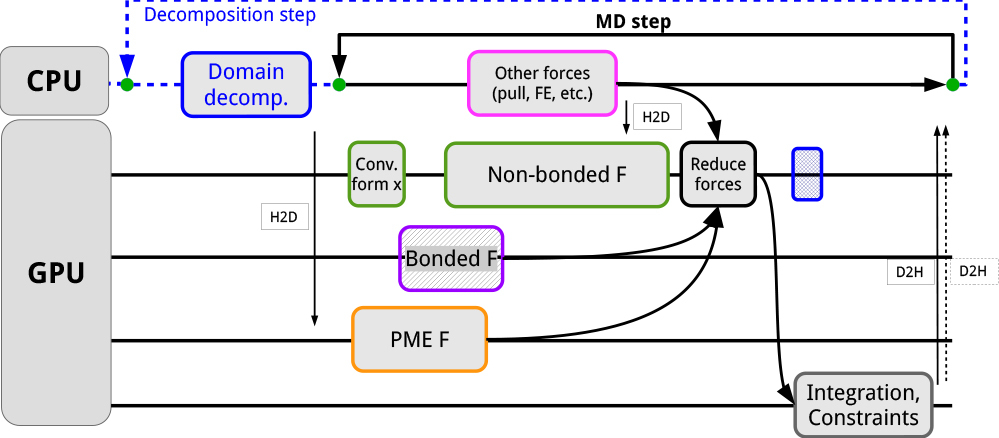
The force-offload scheme relies on shifting the most compute-intensive computations to the GPU, combining it with a multi-level load balancer to optimise CPU–GPU execution overlap to maximise GPU utilisation. It relies on the CPU for integration, which requires frequent CPU–GPU data movement every iteration. With an increasing fraction of computational power being delivered by GPUs, and because CPU–GPU interconnect performance has been lagging behind the actual computational performance, the new GPU-resident scheme was designed with the aim of minimising reliance on CPU resources and stopping the intra-node interconnect from becoming a bottleneck. This algorithm prioritises keeping the GPU busy and avoiding CPU–GPU data movement. To do so, the integration was offloaded, allowing the molecular simulation state to remain resident on the GPU for tens to hundreds of iterations. Importantly, the heterogeneous design is maintained, and the CPU can still be used, but in a reduced role, primarily to execute tasks associated with auxiliary features not ported to the GPU. As an additional benefit, direct GPU communication (also called GPU-aware) could be implemented efficiently (see figure below). This allows data to be transferred directly between GPUs instead of staging through the CPU, which is key to making use of fast GPU interconnects (like NVIDIA NVLink or AMD Infinity Fabrik links). Direct GPU communication also improves inter-node communication latency, especially on systems like the Dardel GPU partition where the network is directly connected to the accelerators and can free up CPU cycles otherwise used for coordinating data staging.
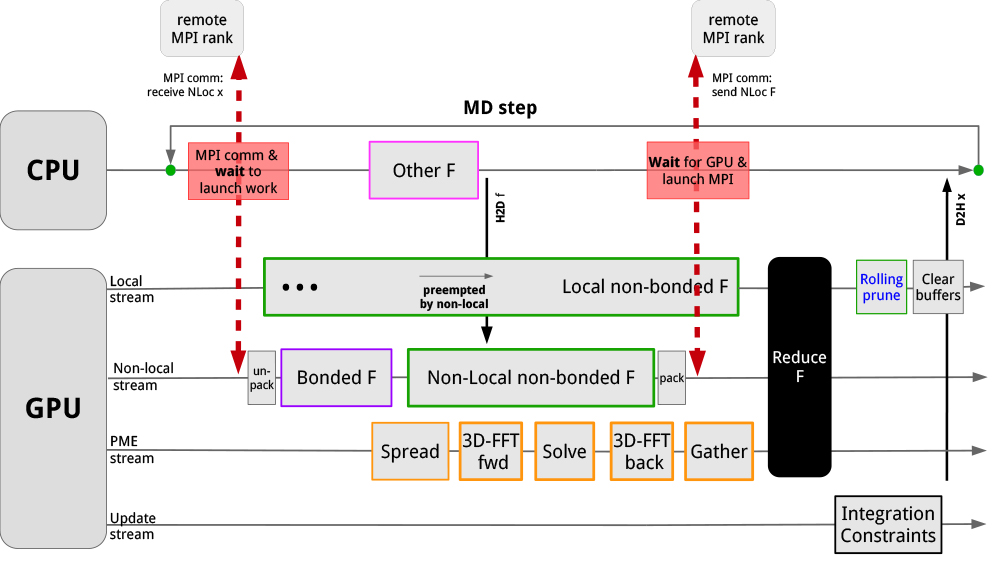
These long-term algorithmic efforts focusing on heterogeneous architectures have made GROMACS well-prepared for the exascale HPC landscape, but adapting a large codebase to new architectures is not without challenges. The new GPU platforms and the programming models for these proved to require significant effort. Depending on the programming language of the codebase and the desired level of abstraction, a range of choices is available to exploit GPU accelerators: accelerated libraries, preprocessor directives, standard language support, and direct programming languages/APIs. Only the latter is able to provide the level of performance and scheduling control required in GROMACS (and similar codes). Its C++17 codebase puts GROMACS in a favourable position because most direct accelerator programming languages and APIs are built on, or compatible with, C++.
The initial GPU support in GROMACS was built on NVIDIA CUDA, the most robust and best-performing choice at the time. NVIDIA GPUs have been the dominant accelerator architecture for over a decade, and CUDA is established as a mature and widely used GPU programming framework. However, to ensure portability of the GROMACS codebase, an open standard-based OpenCL backend was added early on in 2015 with AMD and NVIDIA GPU support first, which was extended to Intel later. Although NVIDIA GPUs have continued to dominate, GROMACS has maintained its commitment to portability through its OpenCL backend. A GPU portability abstraction layer has also been gradually developed to reduce code duplication, to abstract details of GPU APIs, and to prepare the code for new backends in anticipation of a diverse accelerator future.
In recent years, both AMD and Intel joined the GPU accelerator market, and both vendors introduced new heterogeneous programming frameworks with OneAPI and ROCm, respectively. For direct programming of GPU accelerators, AMD developed HIP, a CUDA-like language, and ROCm also ships OpenCL support. The Intel OneAPI toolkit offers OpenCL and SYCL, which is based on DPC++. SYCL is a framework based on open industry standards (like OpenCL), although Intel is one of the major vendors behind it, and while SYCL is still evolving fast, it has several implementations (three major ones and another eight in development at the time of writing) and therefore SYCL code can already target a wide range of hardware including AMD, Intel and NVIDIA GPUs [6]. Although ROCm (and hence HIP) has an open-source code-base, it is only supported by a single vendor and software stack (although, with limitations, it can be used as an abstraction on top of CUDA for NVIDIA GPUs). Both HIP and SYCL are based on C++ and use a single-source model.
With heterogeneous HPC systems based on these new architectures on the horizon, GROMACS needed to extend its GPU backend to support the new Intel and AMD GPU architectures. While the existing OpenCL backend was a reasonable option on the new GPU platforms, the C-based OpenCL kernel language has long been cumbersome in the native C++ GROMACS codebase. In addition, first-class OpenCL support in AMD’s ROCm stack was unclear for some time (although more recently support has been confirmed). To maintain portability, achieve good performance, and have good integration in the C++ codebase, an obvious choice would be to adopt both SYCL and HIP.
With the Swedish e-Science Research Centre (SeRC) and Intel forming a oneAPI academic centre of excellence (CoE) in 2020, SYCL adoption started by extending the GROMACS GPU backend with DPC++ support for Intel GPUs, with an initial release in 2021. Based on the experience gained during that endeavour, we decided to aim at also adopting SYCL as the multi-vendor GPU portability backend to replace OpenCL. This was possible thanks to a fast-developing SYCL standard and promising multi-vendor support. We recognised early on that SYCL code developed with the DPC++ toolchain for Intel needs additional effort to ensure its portability. Early work used hipSYCL [7] as a second SYCL implementation to validate and strengthen the portability of the new backend.
The most appropriate way to support AMD GPUs remained unclear and, to decide how to achieve that, in early 2021 we carried out an in-depth assessment of the available solutions, taking into account short- and long-term factors including portability, performance, proprietary versus standards-based solutions, and available development resources. The team was hesitant to take on the major effort of adding an additional GPU backend based on HIP just for AMD GPUs, as that would involve a commitment to maintaining a total of four GPU backends. Although it is deprecated, OpenCL still requires maintenance, and CUDA is expected (at least in the near term) to be essential for compromise-free performance and robustness on the NVIDIA GPUs used by a large part of the GROMACS user-base.
Following a careful technical evaluation and risk analysis, in mid-2021 the GROMACS team decided to use SYCL in production on AMD GPUs through hipSYCL for the upcoming releases, with the primary focus being the Dardel GPU and LUMI HPC architectures [8]. The decision is both a vote for portability and open standards, as well as an effort to maintain a sustainable expansion of the codebase. Instead of pouring the team’s limited development resources into adding multiple new backends, as well as optimising these for the target platforms, we opted to devote more resources to code modernisation and improving the GPU abstraction layer, as well as the robustness of the asynchronous offload parallelisation.
An important feature of hipSYCL is its strong reliance on the platform-native toolchains, making it possible to mix native (HIP or CUDA) code with SYCL and importantly enabling the use of native development tools (like CUDA and HIP profilers and debuggers). Thanks to this, our early performance evaluation prototype, which was developed to inform the decision to adopt hipSYCL, showed good performance and relatively smooth development. The early hipSYCL prototype, which was released in mid-2021, was a joint effort between GROMACS developers at the EuroCC National Competence Centre Sweden (ENCCS), PDC, and the Intel oneAPI CoE. Since then, thanks to being able to devote a significant amount of resources to the SYCL backend, development has focused on the GPU portability layer, feature completeness of the SYCL backend, build system integration, and automated testing.
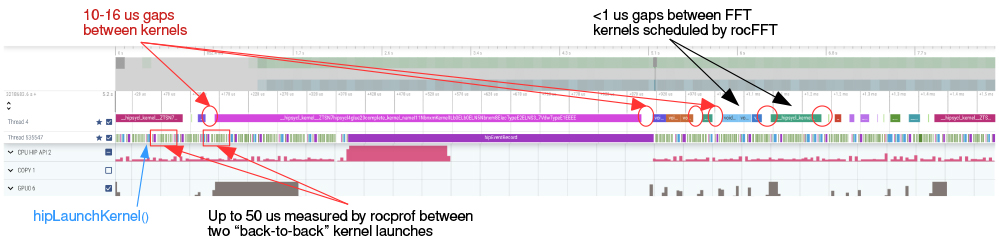
GROMACS 2022 was released with GPU-resident SYCL support that was close to feature-complete. As the primary hardware platforms were still not available and software stacks were still lacking maturity, performance was tracked, but it was only of secondary focus for this release. Tuning for the target platforms and optimising multi-node parallelisation was left to a later stage. These aspects were focused on during the Dardel HPE hackathon in February 2022, where we greatly improved the performance of the SYCL compute kernels on AMD GPUs. It is now overall on par with the native HIP kernel performance. (AMD kindly provided access to their internal HIP GROMACS port as a baseline for the performance comparisons.) However, as shown in the figure above, application performance is still lagging behind. Performance analysis and profiling revealed that the source of the overheads (see graphs below) is in the hipSYCL runtime’s scheduling heuristics. The plan is to improve those with the help of the hipSYCL team. Furthermore, a prototype SYCL implementation of the direct GPU communication layer was successfully evaluated using the Cray GPU-aware MPI during the hackathon on PDC’s HPE test platform. This work identified a set of improvements needed in the vendor software stack, as well as in the GROMACS SYCL backend.
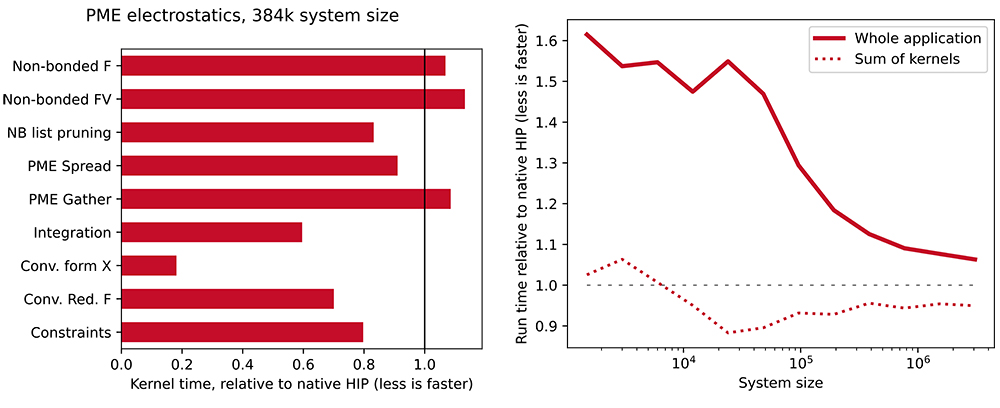
The GROMACS project chose a somewhat unconventional path to supporting AMD GPUs, but this made it possible to focus on long-term goals. As our long-term experience with multi-platform OpenCL support shows, sharing as much code as possible across platforms can greatly ease porting and has long-term maintenance advantages. In our experience, it is the GPU API-specific code (like device detection and task scheduling) that has taken the most effort to develop and maintain, but this also lends itself well to being shared across platforms. In comparison, low-level code (like GPU kernels) generally needs vendor or even device-specific optimisation to achieve good performance, whether it is written in HIP, OpenCL, or SYCL. Moreover, relying on open standards-based languages and APIs whenever possible (not just for GPUs), like MPI, OpenMP, C++, OpenCL and SYCL has strong additional benefits. We recognise that hipSYCL adds an extra software layer on top of the native runtime, which can lead to performance trade-offs in the short-term. We believe that the long-term benefits of our approach outweigh such short-term drawbacks, both for developers and users of GROMACS. Furthermore, the option of a different SYCL implementation with AMD support [9] is available, and adding a native HIP backend also remains a long-term option if warranted.
GROMACS is well on track to being ready for the AMD heterogeneous architecture at the heart of the Dardel system at PDC, which will support the molecular simulation research community in being early users of Dardel (and other new systems with similar architectures). This is a brand-new platform with a new software environment, so testing and stabilisation work is still ahead of us.
The GROMACS team maintains a stable hardware-enablement branch based on the 2022 release [10], which includes the majority of the recent SYCL improvements, most of which are too disruptive for a maintenance patch release. This code branch has stronger stability guarantees than the main branch (where active development for the upcoming 2023 release is carried out), and our aim with this branch is to make it possible for researchers to make early use of the branch on AMD and Intel GPUs, and thereby enable early use on the PDC and LUMI systems even before the next major release which is planned for early 2023.
References
- top500.org/lists/top500/2022/06
- S. Páll & B. Hess. “A Flexible Algorithm for Calculating Pair Interactions on SIMD Architectures.” Computer Physics Communications 184, no. 12 (December 2013): 2641–50. doi.org/10.1016/j.cpc.2013.06.003
- S. Páll, A. Zhmurov, P. Bauer, M. Abraham, M. Lundborg, A. Gray, B. Hess & E. Lindahl. “Heterogeneous Parallelization and Acceleration of Molecular Dynamics Simulations in GROMACS.” The Journal of Chemical Physics 153, no. 13 (7 October 2020): 134110. doi.org/10.1063/5.0018516
- C. Kutzner, S. Páll, M. Fechner, A. Esztermann, B. L. de Groot & H. Grubmüller. “Best Bang for Your Buck: GPU Nodes for GROMACS Biomolecular Simulations.” Journal of Computational Chemistry 36, no. 26 (5 October 2015): 1990-2008. doi.org/10.1002/jcc.24030
- C. Kutzner, S. Páll, M. Fechner, A. Esztermann, B. L. Groot & H. Grubmüller. “More Bang for Your Buck: Improved Use of GPU Nodes for GROMACS 2018.” Journal of Computational Chemistry 40, no. 27 (15 October 2019): 2418-31. doi.org/10.1002/jcc.26011
- Khronos SYCL: www.khronos.org/sycl
- hipSYCL: github.com/illuhad/hipSYCL
- enccs.se/news/2021/09/gromacs-adopts-hipsycl-for-amd-gpu-support
- www.olcf.ornl.gov/2021/06/17/argonne-and-oak-ridge-national-laboratories-award-codeplay-software-to-further-strengthen-syclx2122-support-extending-the-open-standard-software-for-amd-gpus
- GROMACS 2022-HWE branch: gitlab.com/gromacs/gromacs/-/tree/hwe-release-2022
This work is licensed under a CC-BY 4.0 License .