Artificial Intelligence Frameworks on the New Dardel GPU Partition
Xavier Aguilar, PDC
The new Dardel graphics processing unit (GPU) nodes are finally online and open for all users. Each one of these nodes includes an AMD EPYC™ processor with 64 cores and four AMD Instinct™ MI250X GPUs. These AMD GPUs can perform up to 383 TFLOPS for half-precision floating-point format (FP16) and 95.7 TFLOPS for single-precision floating-point format (FP32) when using matrix operations, which are fundamental building blocks for machine learning. So these GPU nodes are a very suitable platform for running artificial intelligence (AI) workloads at PDC.
PDC has preinstalled several containers with the most popular AI frameworks, for example, PyTorch[1] and Tensorflow[2]. These containers have multi-GPU support, and therefore, users have the possibility to train and run their AI models on Dardel using multiple GPUs in parallel. In addition, users are able to download these containers to their workstations, customise them as they please, and then upload them back to Dardel. Furthermore, if a containerised solution is not the best fit for you, you can instead have your own local installation of your preferred AI framework. If that is the case, just get in touch with PDC’s Support team (via email to support@pdc.kth.se), and we will help you to get your framework set up and running.
We have performed several experiments at PDC to measure the performance of one of these AI frameworks with the AMD GPU backend using three popular AI models. Moreover, we ran the same experiments on another supercomputer cluster using NVIDIA GPUs in order to compare both GPU backends. The first table below presents the hardware and software specifications for these two clusters. The second table shows an overview of the specifications for the GPU cards used in our experiments: AMD MI250Xs and NVIDIA A100s.
AMD Cluster |
NVIDIA Cluster |
|
|---|---|---|
GPU |
4 × MI250Xs |
4 × A100s |
CPU |
1 × AMD EPYCTM 7A53 64-core |
2 × 32-core Intel Xeon Gold 6338 |
Memory per node |
512 GB |
256 GB |
Framework |
Pytorch 1.13.0 & Rocm 5.4 |
Pytorch 1.13.0 & CUDA 11.7 |
AMD MI250X |
NVIDIA A100 |
|
|---|---|---|
Peak FP32 performance |
95.7 TFLOPS |
19.5 TFLOPS / 156 TFLOPS |
Peak FP16 performance |
383 TFLOPS |
78 TFLOPS / 312 TFLOPS |
Memory |
128 GB |
40 GB |
Peak Memory bandwidth |
3276.8 GB/s |
1555 GB/s |
The experiments consisted of training three popular models for image classification (Inception-V3, Resnet-101, and Resnet-50) with synthetic data. The training performance was measured using the number of images per second achieved and averaged over ten epochs. (Note that the first epoch is omitted to avoid initialisation overheads.) We measured the performance when using fixed precision (FP32) and when using mixed precision – in this mode, PyTorch converts some operations to FP16 to optimise computations. We used the same hyperparameters for the models on both systems. Our experiments were based on previous benchmarking work performed by SURF[3]. The original code for these experiments can be found in [4].
The graphs below show the number of images per second for each of these models. The green bars are the NVIDIA A100s, and the blue bars are the AMD MI250Xs. The light shades of blue and green are for the fixed precision experiments (FP32), and the darker shades for the mixed precision ones.
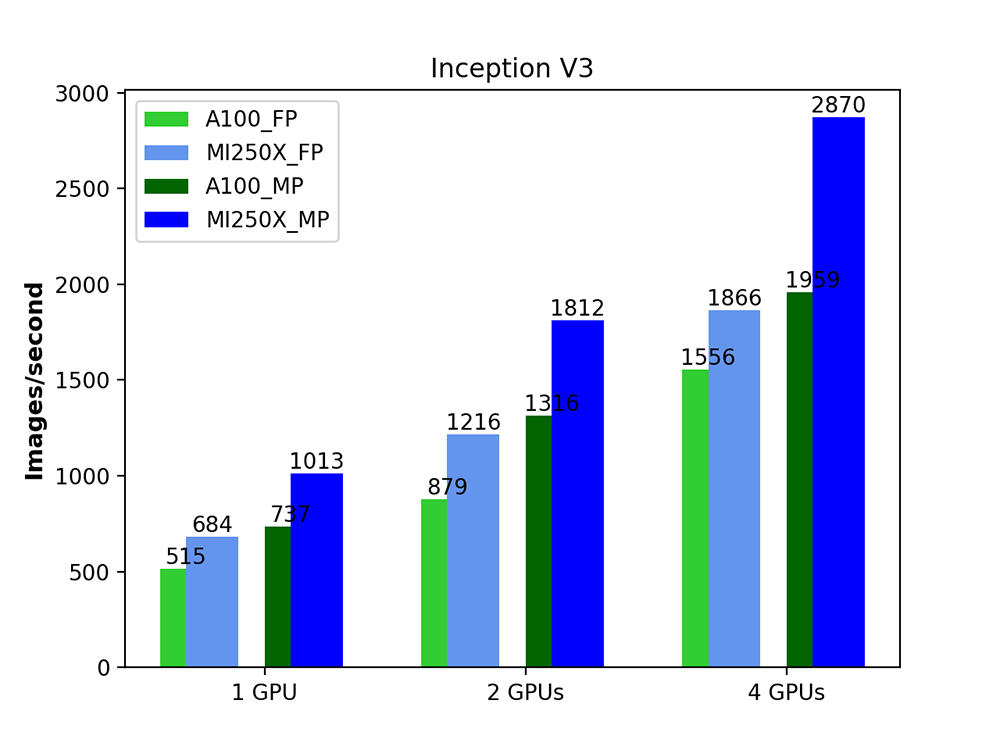
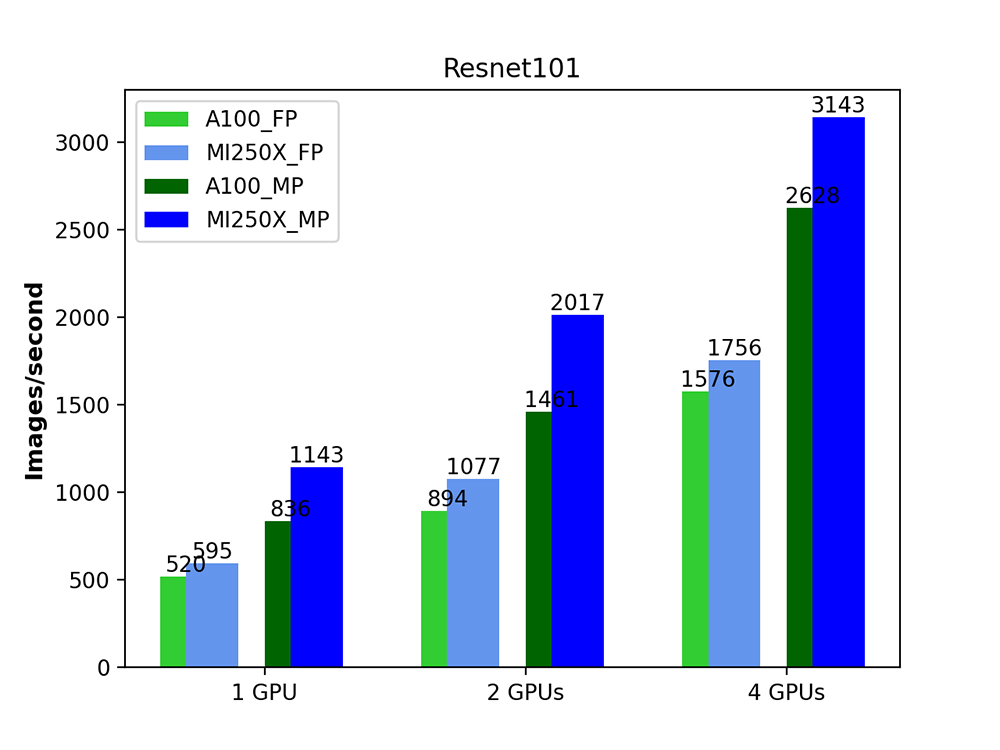
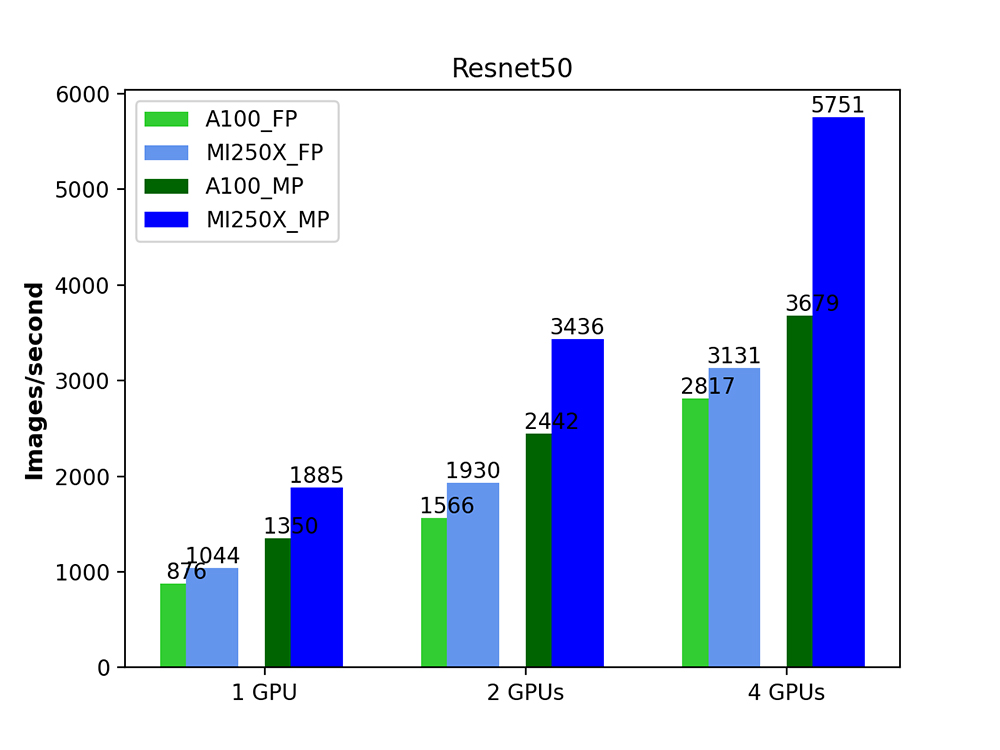
We can see that for the Inception model, the MI250X always outperforms the A100, with the difference in throughput when using mixed precision and all four GPUs being especially remarkable. For the Resnet models, we can again see the MI250X outperforming the NVIDIA A100 in all cases, as a result of its higher specifications and higher theoretical peak performance, as well as a more mature AMD software stack. The figures also show that, for both backends, using mixed precision mode always helps to speed up computations quite considerably.
In summary, the results demonstrate that the new AMD MI250X cards at PDC have an impressive performance for AI model training. This new AMD hardware, together with AMD’s rapidly evolving GPU software stack and the fact that many AI frameworks are compatible with it, might turn AMD into an important player in the field of GPU computing for HPC and AI and might break the monopoly that NVIDIA has had for many years. Having more players in the GPU market, and especially in the GPU for machine learning market, opens up the number of choices for users and, in addition, will potentially hasten the progress of AI frameworks. Take advantage of this opportunity and start using Dardel and its AMD MI250Xs for your machine learning workloads!