
A positive side effect of cache monitoring – doing good rather than evil

As billions of internet users demand immediate, reliable access to high-resolution video and social media content through cloud-based apps, how do you accommodate ever increasing network speeds? A team of KTH and Ericsson researchers found a new way to get networks to process data packets through the more effective use of last-level cache memory. And the answer was found using the same tools as those used for Spectre and Meltdown.
In a data-driven age of ever-faster connectivity, link speeds are accelerating, with 100Gbps becoming common and soaring towards the Tbps level anticipated by the mid-2020s. As packets arrive at an ever higher rate, around 100 million servers in the world’s data centres are under increasing pressure to process these packets efficiently. The introduction of 5G connectivity, IoT, machine-to-machine communication, and the digital transformation of industry will introduce even more packets, thus putting even more load on service providers’ network assets and increasing the demand on public cloud infrastructures, such as those of Google, Microsoft, and Amazon.

“At the moment, a server receiving 64-byte packets at 100Gbps has just 5.12 nanoseconds to process each packet before the next one arrives,” says Alireza Farshin, a doctoral student at the KTH Network Systems Laboratory. He is one member of a group of researchers who have spent the past year looking into how to process packets faster.
The fact that the arriving packets are not processed fast enough not only impacts the ever-increasing numbers of IoT devices, but also frustrates device and network users who have to put up with everyday annoyances such as playback problems and loading delays, gaming glitches and video stutter. And let’s face it, who wants to wait a second longer than necessary to complete their order when making an online purchase when it’s meant to be convenient?
A question of cache
The good news is that Farshin and his colleague Amir Roozbeh, an industrial doctoral student from Ericsson Research, figured out a solution to the problem which in simple terms involves the efficient use of existing hardware. More specifically, they have researched how to make the most of last-level cache (LLC) in Intel processors. In other words, the necessary hardware is already in place.
Dejan Kostic, Professor of Internetworking at KTH Royal Institute of Technology, who is head of the Communication Systems Division of KTH’s School of Electrical Engineering and Computer Science and also the research team’s principal investigator, says: “If we place data in the right cache slice in the CPU, we can access it faster, hence process more packets and reduce the latency of our apps.”
Farshin says: “To keep within the 5-nanosecond time budget, the significance of cache memory cannot be underestimated.” This is especially true given the high expense of accessing main memory.
CacheDirector: the slice-aware network I/O solution
Farshin and Roozbeh’s research (which is overseen by Kostic and co-advisor Professor Gerald Q. Maguire Jr.) has led to their discovery of how to maximize the performance extracted from the LLC cache memory shared among all the cores in the central processing unit (CPU) of an Intel processor.
“With networking link speeds accelerating towards 400Gbps or even 1Tbps, we must ensure the levels of performance that society expects today, and we’ve figured out how to deliver the performance users need,” says Maguire, who seems blessed with a quiet kind of confidence. “The good news is, we’ve discovered how to make data centres fast, energy efficient, and cost effective. The disaggregation of data centres has been among the driving forces for Ericsson’s investment in our team’s work.”
Bubbling with enthusiasm, Kostic has a somewhat more dramatic way of expressing the team’s success: “Data centres consume as much energy as the aircraft industry, and the energy savings that our method can enable are significant. We see up to a 5 per cent efficiency increase: roughly 5 watts per CPU. If you consider that there are about 100 million processors at data centres worldwide, that is equivalent to the electricity generation of a typical coal-fired power plant.”
No wonder the team’s work has raised the interest of the computer architects. Because as Kostic says, “It’s about to have a massive impact on the world.” This impact could well be felt fast because, with the hardware already in place, it’s simply a matter of making some software changes.
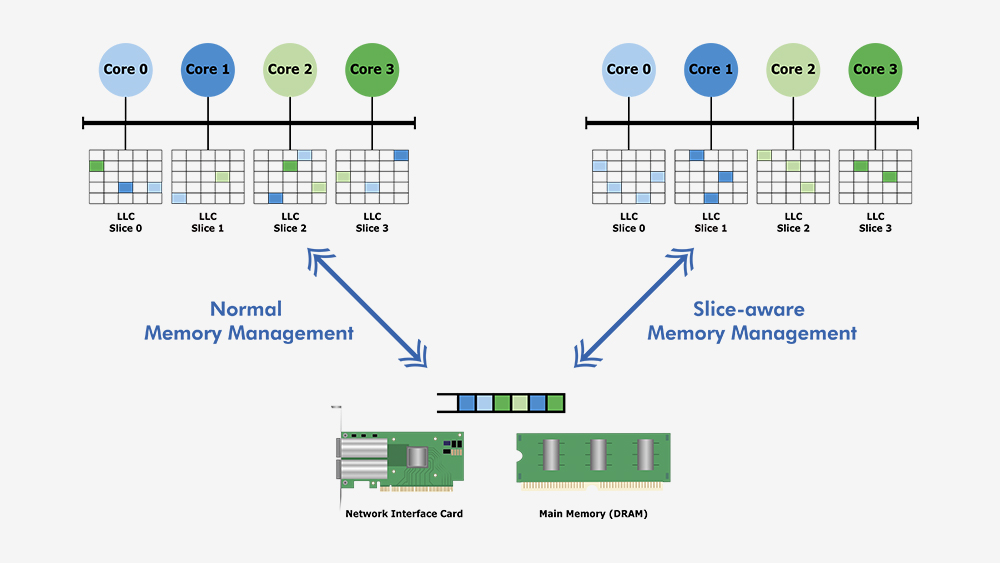
The team has devised a slice-aware memory-management scheme which allows frequently used data to be accessed more quickly via the LLC of a computer’s CPU. By establishing a key-value store and allocating memory in a way that it maps to the most appropriate LLC slice, they have demonstrated that this improves the performance of the key-value store. The team used the proposed scheme to implement a tool called CacheDirector, which makes Data Direct I/O (DDIO) slice-aware.
This is a significant step forward given that, until now, Data Direct I/O (DDIO) has sent packets to random slices, which is far from efficient. Given today’s non-uniform cache architecture (NUCA), the cache-management solution is invaluable. For example, when combined with the team’s introduction of the concept of dynamic headroom in the Data Plane Development Kit (DPDK), the packet’s header can be placed in the slice of the LLC that is closest to the relevant processing core. As a result, the core can access packets faster while also reducing queuing time.
“We exploit the presence of non-uniform ‘slices’ in the last-level cache of Intel microprocessors to introduce slice-aware memory management,” says Farshin. “Our work demonstrates that taking advantage of nanosecond improvements in latency can have a large impact on the performance of applications running on already highly-optimized computer systems.” The team found that for a CPU running at 3.2GHz, CacheDirector can save up to around 20 cycles per access to the LLC which amounts to 6.25 nanoseconds. This accelerates packet processing and reduces tail latencies of optimized Network Function Virtualization (NFV) service chains running at 100Gbps by up to 21.5 per cent.
In reducing access time to the LLC, the team has revealed a key opportunity that has remained hidden in Intel CPUs for the past 10 years. Cloud and network providers would be foolish not to embrace it. And with ready access to the source code and the hardware already in place, it won’t cost them a thing.
More details are available in the EuroSys 2019 conference publication . You can access the source code for CacheDirector here .
Patents pending
The work on CacheDirector complements earlier collaborative research projects carried out by several teams led by Dejan Kostic at KTH. Their combined efforts have led to:
- CacheDirector
- Metron – a NFV platform designed to deeply inspect traffic at 40Gbps, carry out early data classification and apply a tag to each packet. This enables the hardware to accurately dispatch traffic to the correct CPU core based on the tag, bringing the multiple benefits of load balancing, elasticity and flexible traffic screening.
- Synthesized Network Functions – exploiting this enables the realisation of a highly optimised traffic classifier by synthesising internal core operations while eliminating redundancy.
“The synergy between these various projects was fairly unexpected,” says Kostic. “I’m delighted that our ground-breaking work in collaboration with Ericsson has resulted in several patent applications.” These include the following:
- A. Roozbeh, A. Farshin, D. Kostic, and G. Q. Maguire Jr., “Last Level Cache (LLC) aware Memory Allocation,” Patent, Jun. 21, 2018, WO – PCT/SE2018/050676.
- A. Roozbeh, A. Farshin, D. Kostic, and G. Q. Maguire Jr., “Application-agnostic slice-aware memory optimization at run-time,” Patent, Dec. 13, 2018, WO – PCT/SE2018/051311.
- A. Roozbeh, A. Farshin, D. Kostic, and G. Q. Maguire Jr., “Dynamic slice selection function,” Patent, Feb. 14, 2019, US 62/805,552.
The latest research has been funded by the Swedish research initiative the Wallenberg AI Autonomous Systems and Software Program (WASP), Swedish Foundation for Strategic Research, as well as the European Research Council (using the European Union’s Horizon 2020 resources).
Contact



Writer: Birgitte van den Muyzenberg